0. conda를 이용하여 orange를 설치하였다면 seaborn을 사용할 수 있습니다.
1. Orange의 Canvas를 아래와 같이 배치하고 Python Script를 선택하고 아래내용을 입력합니다.

2. Script 내용
import pandas as pd
from Orange.data.pandas_compat import table_from_frame
import matplotlib.pyplot as plt
import seaborn as sns
penguins = sns.load_dataset("penguins")
out_data = table_from_frame(penguins)
sns.relplot(x="bill_length_mm", y="body_mass_g", hue="species", data=penguins)
plt.show()
2.1 import seaborn as sns 에서 Package Error 가 나면
터미널에서 conda install seaborn하여 package를 설치하면 됩니다.
3. Script를 실행하면 아래와 같은 결과를 확인 할 수 있습니다.

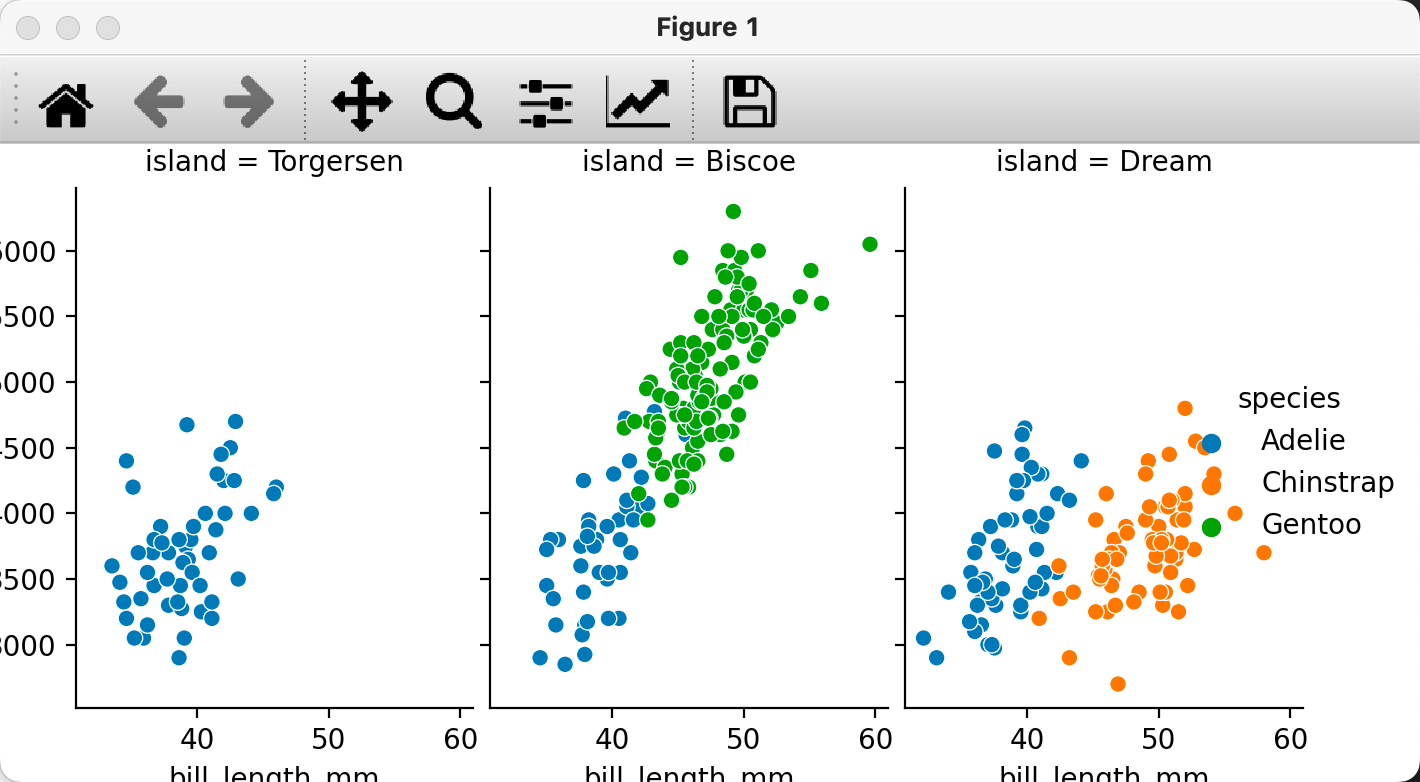
5. 역시 아래와 같이 약간 복잡한 그래프를 그릴 수도 있습니다.
sns.relplot(x="bill_length_mm", y="body_mass_g", hue="species", col="island", data=penguins)