매일 파이썬코딩을 하는 사람이 아니면 머신러닝을 Orange3로 학습하면 좋겠다는 생각입니다. 그런데 오렌지의 위젯은 정해진 틀에서 작동하므로 유연성이 부족합니다. 그래서 조금만 깊게 들어가면 파이썬의 도움이 필요하다는 생각입니다. 오렌지에서는 이것을 쉽게 해결해줄 수 있는 방법이 있는데 Python Script가 있습니다.(파이스크립트는 3.32 기준으로 Transform에 있음)
아래에서 파이썬스크립트를 활용하는 방법을 살펴봅니다.
0. 환경 만들기
0.1 miniConda를 설치합니다. https://docs.conda.io/en/latest/miniconda.html#
0.2 VSCode를 설치합니다. https://code.visualstudio.com/
1. 미니콘다가 설치되어 있으면 오렌지3 가상환경을 만들고 액티브합니다.
$명령어창(윈도우)에서(맥은 터미널) $conda env list 명령을 실행하여 현재 가상환경을 살펴보고 없으면 orange3라는 가상환경을 만듭니다
$ conda create -n orange3 python=3.8.13 #타임시리즈 위젯사용을 위해 구버전 설치
$ conda activate orange3 #orange3 가상환경으로 이동합니다.
(orange3) C:\user\gilson>_ #orange3 가상환경으로 들어 왔습니다.(윈도우)
(orange3) $ pip list # 또는 conda list #현재 설치되어 있는 package를 살펴봅니다.
(orange3) $ pip install scipy==1.7.3 #타임시리즈 위젯사용을 위해 구버전 설치
(orange3) $ pip install orange3==3.32 #2022년04월26일 현재 최신버전
(orange3) $ orange-canvas& (윈도우에서는 & 대신 ";"을 또는 필요없음)
(orange3) $ code .
만약 vscode가 실행이 안되면 맥은 VSCode 설정에서 "shell command" 설정을 하면 되고, 윈도우에서는 path설정이 제대로 되었는지 확인합니다.
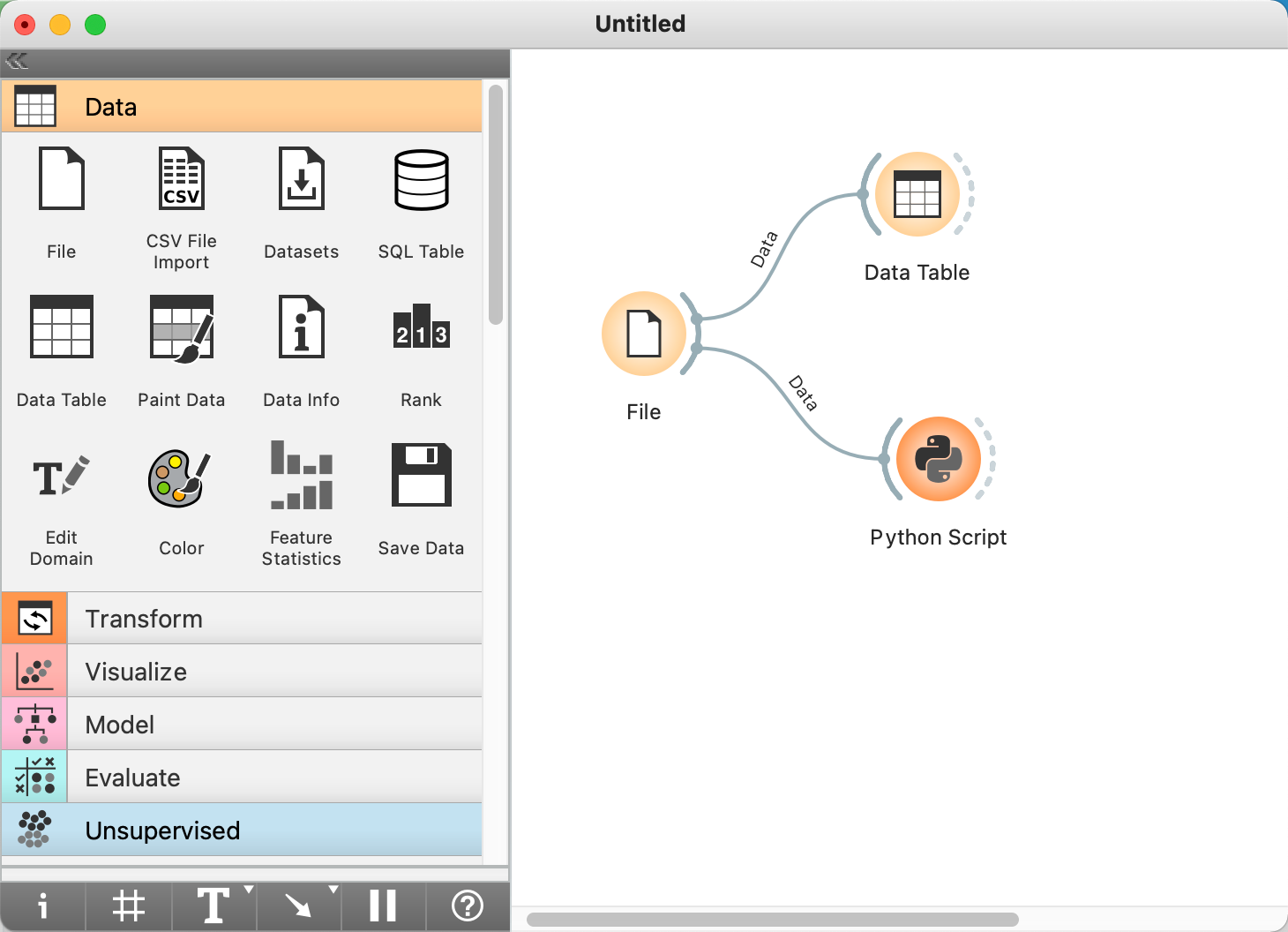
이제 오렌지3와 VSCode를 같이 실행할 수 있습니다. 굳이 VSCode를 같이 실행하는 이유는 오렌지의 파이썬스크립트가 AutoComplete 기능과 Code Insight 기능이 없어서입니다. 아래 이미지를 참조하여 보십시요.
2. 오렌지의 파이썬 스크립트 활용
2.1 오렌지3를 실행하고 > 파이썬스크립트 위젯을 캔바스에 드롭하고 > 파이썬스크립트 위젯을 더블크릭합니다.
2.2 VSCode에서 exam.ipynb 파일을 만든 다음 > Kernel을 지정하라고 하면
위와 같이 orange3의 가상환경의 python 인터프리터를 지정합니다.
제대로 되었는지는 아래 그림과 같이 확인 할 수 있습니다.
2.3 스크립트의 내용을 복사하여 VSCode에 붙여 넣습니다. 그리고 이미있는 내용을 참조하여 파이썬 코드를 작성하고 컨트롤+리턴키로 셀을 실행하여 결과를 확인합니다.
2.4 원하는 결과가 나오면 셀내용을 복사하여 오렌지3의 파이썬 스크립트 에디터에 붙여넣기하고 스크립트 왼쪽아래의 [런버튼]을 크릭하여 실행합니다. 아래그림을 확인해보세요.
2.5 이와 같은 변환은 자주하기 때문에 이 형식을 저장하여 두었다가 사용하면 좋겠지요. 파이썬 스크립트 화면에서 아래 그림과 같이 하여 저장해 둘 수 있습니다.
2.6 당연히 불러오기도 됩니다.
2.7 Update 버튼을 크릭하면 스크립트 내용을 바꿀 수 있겠죠.
3. 넘파이보다는 판다스사용이 좋으시면 이렇게 하면 됩니다. 이번에는 입력데이타가 있는경우입니다.
3.1 VSCode에서 실행하고 결과를 확인합니다.
3.2 코드보기
import Orange.data.pandas_compat as p
# 오렌지의 in_data를 가상으로 만들어 줍니다.
# 오렌지에 붙여 넣기 한 후에는 실행이 안되게 합니다.
idf = p.pd.DataFrame({'x': [1,2,3,4,5],'y': [1,2,3,4,5]})
in_data = p.table_from_frame(idf)
# 아랫부분이 오렌지에서 실행됩니다.
idf = p.pd.concat(in_data.to_pandas_dfs(), axis=1)
idf = idf[:3] # 이런방법으로 pandas를 활용하면 됩니다.
out_data = p.table_from_frame(idf)
3.3 역시 자주 사용되는 형식이므로 저장하여두겠습니다.
3.3 저장할때 한글이 들어가있으면 별도의 에디터프로그램에서 .py 파일을 불러온다음 utf-8로 저장하여야 정상으로 읽어옵니다.
4. VSCode를 사용하지 않고 idle를 사용할 수도 있다. 다만 idle은 conda의 orange3 가상환경에 있는 idle을 실행해주어야 Orange.data.pandas_conpat 를 import 할 수 있습니다.
저같은 경우에는
C:\Users\gilso\.conda\envs\orange3\Scripts\idle.exe
에 있습니다. (맥에서는 곧바로 실행이 되는데 윈도우에서는 다른곳의 idle이 실행이 되는군요. 아마도 패스문제 이겠지요. 그래도 가상환경내의 실행파일이 실행되야 맞지않나...
5. feature 와 target으로 분리하려면 아래와 같이하면 됩니다.
import numpy as np
from Orange.data import Table, Domain, ContinuousVariable, DiscreteVariable
x1 = DiscreteVariable("size", ["small", "big"])
x2 = ContinuousVariable("height")
x3 = DiscreteVariable("shape", ["circle", "square", "oval"])
y1 = ContinuousVariable("speed")
domain = Domain([x1, x2, x3], y1)
X = np.array([[1, 3.4, 0], [0, 2.7, 2], [1, 1.4, 1]])
Y = np.array([42.0, 52.2, 13.4])
out_data = Table(domain, X, Y)
6. 참고로 파이썬스크립트에서 Table변수 다룰때 스트링으로 고친다음 인티져로 고쳐야 하는 경우가 있음.
print(num+1)!=print(int(num)+1), print(num+1) == print(int(str(num))+1)임.
! 2022.04.28 01:40 수정함(5번을 추가하였습니다)