Orange3를 엘리쌤과 인공지능에서 알게된후 Python 기초 통계를 공부하면서 최대한 Orange3로 따라하면서 통계도 공부하고, 오렌지도 공부하고 덩달아 파이썬도 익히는 시간을 갖기로 하였습니다.
섹션: 카이제곱(chi2)을 오렌지로 따라해봅니다.
1. 데이터는 아래와 같은 형태로 housetasks.tab 이것을 다운로드하고, 오렌지의 캔바스를 아래와 같이 배치하고 연결합니다.
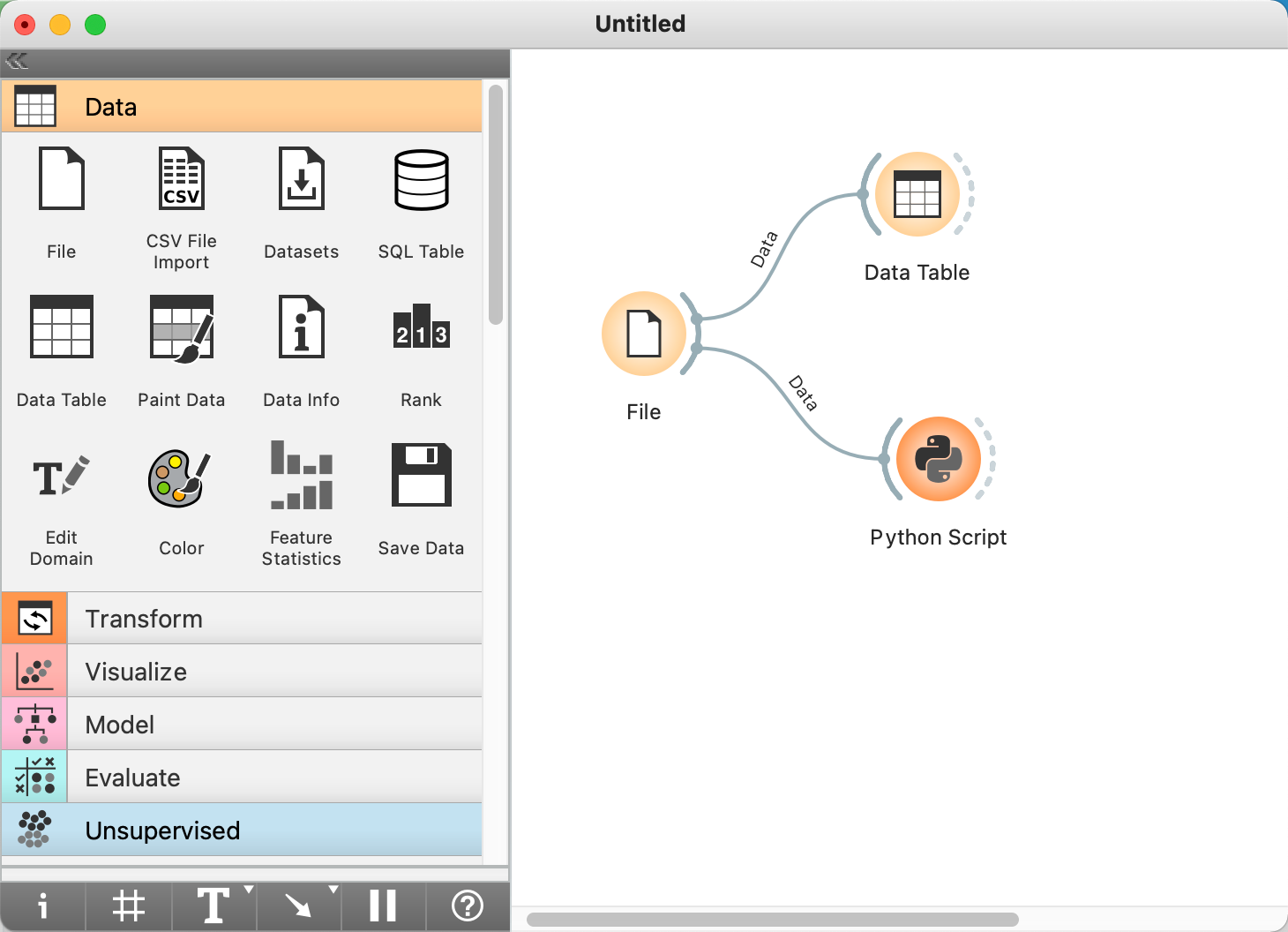
2. File Widget으로 다운받은 파일을 불러오고, Python Widget을 더블크릭하고 아래 내용을 복사하여 붙여넣기 합니다.
[RUN]버튼을 선택하여 결과를 확인합니다.
(1944.4561959955277, 0.0, 36, .....) 검정통계량(독립성 검정), p-value, dof(자유도=(12-1)*(4-1))
귀무가설을 기각하고 대립가설을 채택합니다. 가사는 작업구성과 차이가 있습니다.
2. 카이제곱 검정은 카이제곱 독립성(동질성) 검정과 적합도 검정 2개로 구분되네요( https://www.jmp.com 이하 이곳에서 가져옴)
3. 카이제곱 독립성 검정은 두 변수가 관련될 가능성 여부를 확인합니다. 여기에 범주형 또는 명목형 변수 2개에 대한 개수 값이 있습니다. 또한 두 변수가 관련이 없다고 가정합니다. 검정을 통해 이러한 가정이 타당한지 여부를 판정할 수 있습니다.
- 영화 장르가 첫 번째 변수입니다. 두 번째 변수는 장르별로 관객들이 영화관에서 간식류를 구입했는지 여부입니다. 기본 전제(또는 통계 용어로 귀무가설)는 영화 장르와 관람객들의 간식류 구입 여부 사이에는 관련성이 없다는 것입니다. 영화관 사장은 영화관에 간식류 비축량을 추정하려고 합니다. 영화 장류와 간식류 구매 간에 관련이 없는 경우, 영화 장르가 간식류 판매에 영향을 미칠 경우보다 더 간단히 추정할 수 있습니다.
4. 카이제곱 적합도 검정은 표본 데이터가 특정 이론적 분포에서 추출된 것인지 여부를 확인합니다. 여러 데이터 값들이 표집된 집합이 있고 데이터 값의 분포 양상에 대한 가정이 내려져 있습니다. 카이제곱 적합도 검정은 데이터 값이 가정에 "충분히" 적합한지 또는 가정에 의문점이 있는지 판별하는 방법을 제공합니다.
- 각 봉지마다 캔디가 100개씩 들어있고 5가지 맛 캔디가 고르게 담겨있는 캔디 봉지 10개 가 있습니다. 각 봉지에 맛별로 동일한 개수의 캔디가 들어 있습니다. 검정하려는 가설은 봉지마다 담긴 5가지 맛의 비율이 같다는 것입니다.
5. 오렌지의 데이터세트에 있는 타니타닉생존자 자료에서 남녀간의 생존여부의 차이가 있는지 카이제곱검정을 해봅니다.

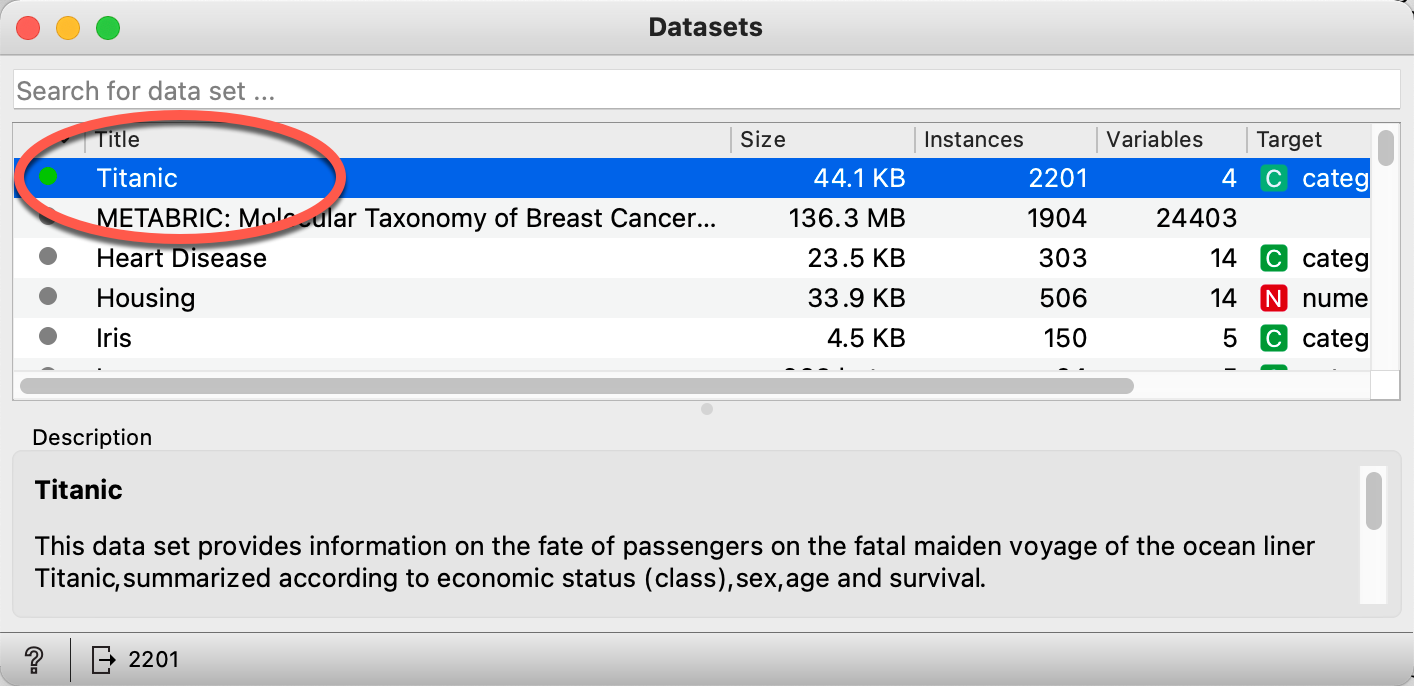
6. Data Table위젯을 더블크릭하여 데이타의 구조를 살펴봅니다.

7. Sieve Diagram(채 다이아그램)위젯을 오렌지 캔바스에 놓고 Datasets와 연결하고 더블크릭한후 아래와 같이 선택합니다.

8. 자료의 갯수가 2201개이고, 카이제곱검정값이 456.87이며, 피값은 0.05 이하입니다. 귀무가설을 기각하고 생존율은 성별에 유의하다고 판정합니다. 4개의 사각형 크기가 다르지요. 사각형 크기는 기대값이고 사각형안의 채(그리드, 그물)의 촘촘함은 관측치입니다.
성별에서 여성의 사각형이 적은 것은 탑승자중 여성의 비율이 낮은것이고, 파란사각형 안의 채(그리드)가 촘촘 한것은 실제 관특치가 많은 것을 보여줍니다. 반대로 남성의 탑승자는 많으나 위 빨강위처럼 채가 듬성듬성한 것은 생존자가 기대값보다 매우 적었다고 해석합니다.



댓글 없음:
댓글 쓰기