앞에서는 데이터를 2로 구분(훈련, 시험)하여 분류했으나 이번에는 3으로 구분(훈련, 시험, 체크)하여 파이썬으로 작업한 것과 완전히 유사한 결과를 얻을 수 있도록 오렌지로 구성해 봅니다.
1. 오렌지의 캔바스에 위젯을 아래 그림과 같이 배치하고 연결합니다.
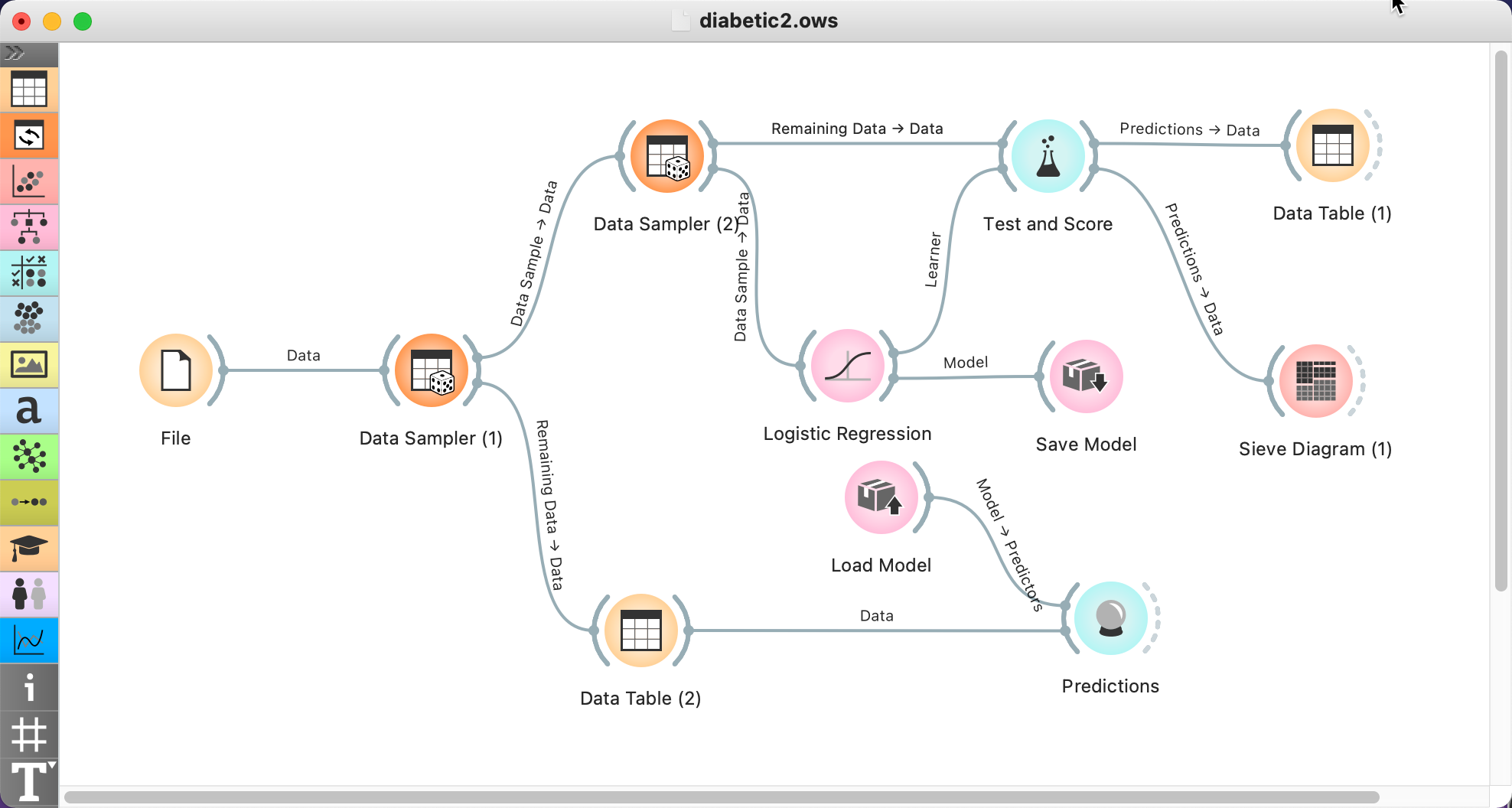
2. File Widget을 선택하여 앞에서 다운 받은 자료를 불러옵니다. Outcome을 target으로 지정하였습니다.

3. Data Sampler (1) Widget을 선택하고 체크 데이터 갯수가 17개(파이썬 분석과 일치 시키기위하여)가 되도록 (2) Fixed sample size = 751을 지정합니다.

4.Data Sampler (2) Widget을 선택하여 Test Data가 100개가 되도록 (2) Fixed sample size = 651을 지정합니다.


6. Save Model Widget을 선택하여 디폴트 파일이름으로 저장합니다.

7. Load Model Widget을 선택하여 방금 저장된 파일을 불러옵니다. 모델을 저장하고 불러오는 것을 익히는 것입니다.

8. Predictions Wedget을 선택하여 체크데이터의 결과를 확인합니다.

(1) Calsses in data를 선택하고 (2)에서 '0'(음성)과 '1'(양성)의 확률을 확인하십시요. 또한 (3)에서 CA = 0.765로 정확도를 확인합니다. 훈련의 테스트결과 0.78임을 보면 과대, 과소 적합은 아닌 것 같군요.
9. 마지막으로 Sieve Diagram (1)을 확인한 다음 입력을 Data Table (2)에서 받게 하고 더블크릭하여 결과를 확인합니다.


(1)번 = Outcome, (2)번 = BloodPresure으로 하였을 때 Outcome이 1(양성=당뇨)일때 (4)번보다 (3)번이 촘촘한것을 확인하시고, Outcome이 0(음성=당뇨가 아님)일때 (6)번보다 (5)번이 더 촘촘함을 확인하십시요. 이것으로 당뇨는 혈압이 높다고 반드시 확률이 높아지는 것이 아니고 오히려 낮아짐을 알 수 있습니다. (앞에서 해결하지 못하던 것을 해결하였습니다. 그런데 이는 17개의 체크데이터 결과임을 유의 하십시요).



댓글 없음:
댓글 쓰기