오렌지3에서 간단하게 Wikiprdia 자료를 읽어 Word Cloud를 해봅니다. 오렌지 예전버전에는 Text Mining에 Wikipedia 자료를 읽어 올 수 있는 위젯이 있었는데 3버전에서는 없어졌네요. 오렌지를 사용하지 않고는 이처럼 환경설정이 복잡해요.
1. 위젯을 아래와 같이 배치합니다.

2. 파이썬스크립트를 아래와 같이 수정하고 [RUN]버튼을 선택합니다.
import Orange.data.pandas_compat as p
import orangecontrib.text.wikipedia_api as wiki
api = wiki.WikipediaAPI()
corpus = api.search('ko',['이재명', '변호사'])
out_object = corpus
위키피디아에서 자료를 검색해 읽어오는데 상당히 긴시간이 소요되네요. 바람개비가 멈출대까지 기다리세요.
3. 데이타테이블위젯에서 첫행을 선택하고
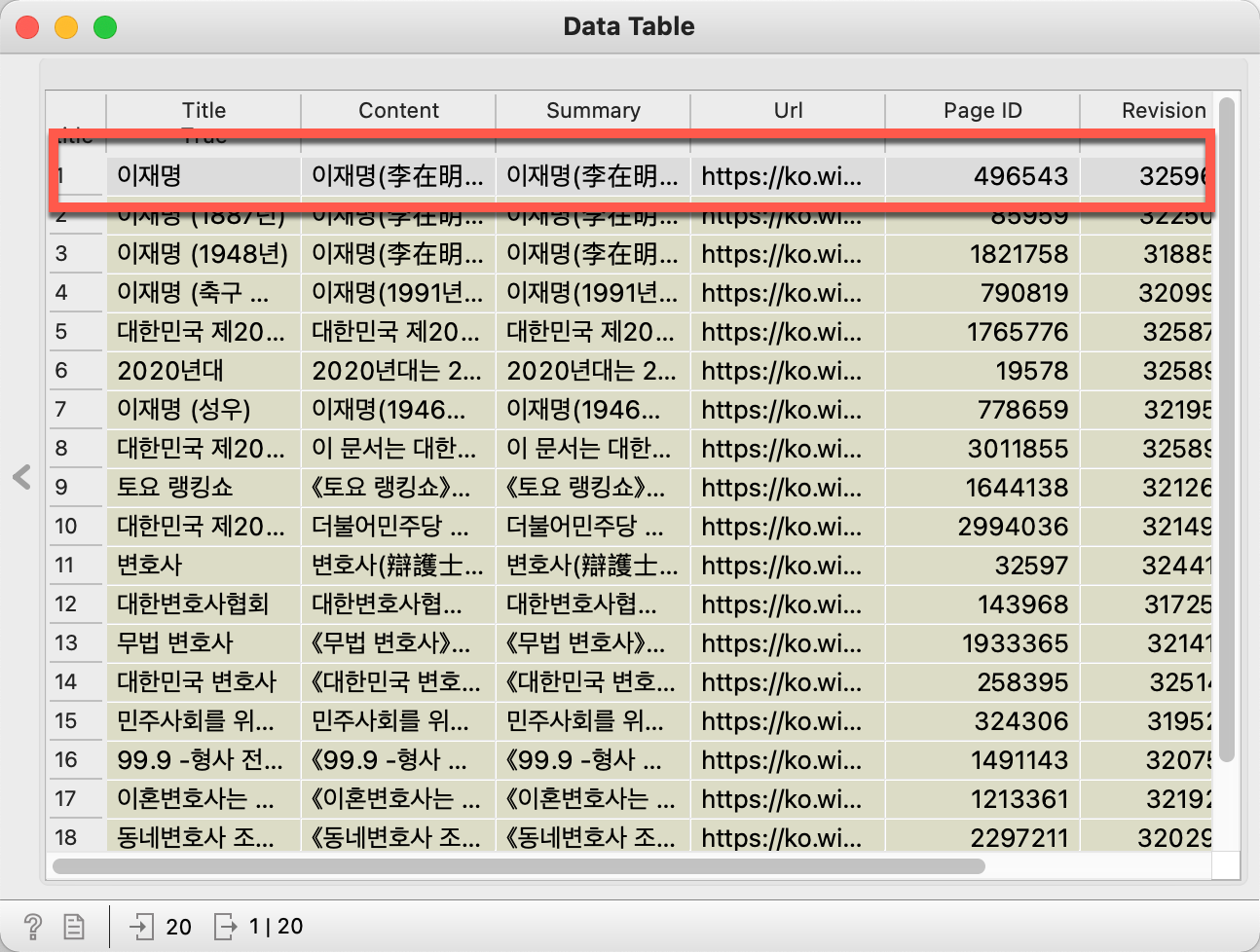

5. Import Documents 위젯을 선택하여 파일을 저장한 폴더를 선택합니다.


6. Corpus Viewer를 선택하여 내용을 확인합니다.

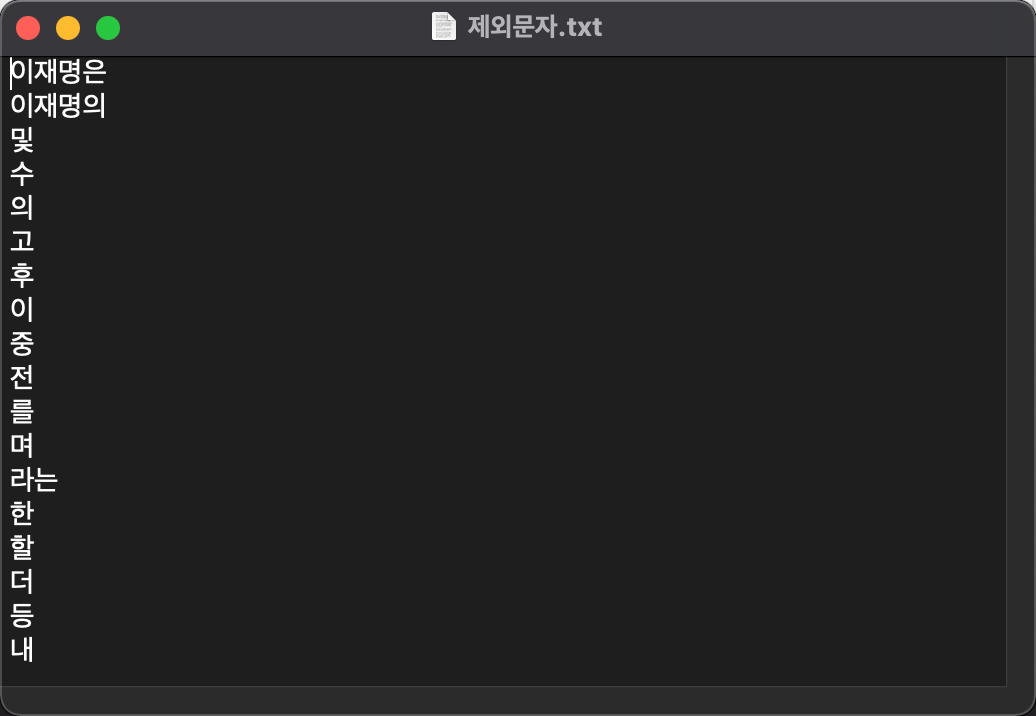
7. Preprocess Text를 선택하여 아래 그림과 같이 Tokenization 과 Filtering을 추가한후 설정을 합니다. 제외문자는 텍스트에디터(맥) 노트패드(윈도우)등으로 아래와 같이 작성하여 저장해둡니다(저는 doc폴더에 저장하였습니다).

8. Word Cloud를 선택하여 내용을 확인합니다.




댓글 없음:
댓글 쓰기