0. 최근접 이웃 알고리즘은 우리가 예측하려고 하는 임의의 데이터와 가장 가까운 거리의 데이터 K개를 찾아 다수결에 의해 데이터를 예측하는 방법이다.

1. 오렌지의 캔바스에 위젯을 위치시키고 연결합니다.
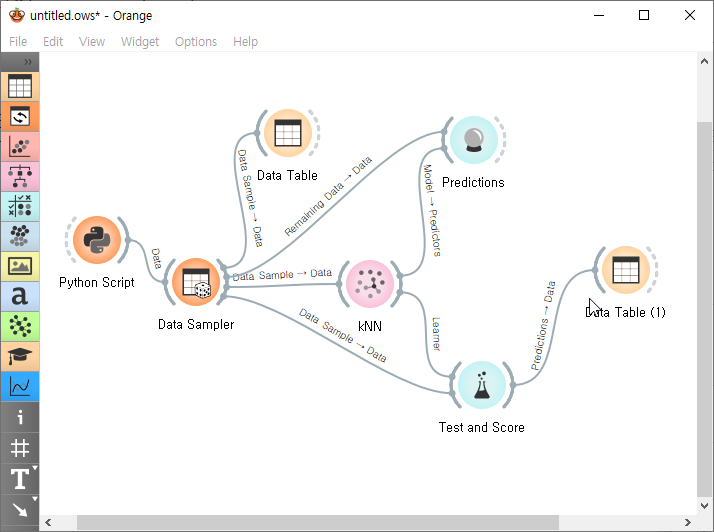
2. 혼자 공부하는 머신러닝+딥러닝에 있는 도미와 빙어자료를 이용하였습니다. 파이썬 스크립트를 더블크릭하고 아래 사항을 입력한다음 [RUN]버튼을 선택합다.
import numpy as np
from Orange.data import Table, Domain, ContinuousVariable, DiscreteVariable
iclass = ContinuousVariable("y")
domain = Domain([ContinuousVariable("x1"),
ContinuousVariable("x2")], iclass)
ix = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0,\
31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0,\
34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5,\
41.0, 41.0, 9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0,\
12.2, 12.4, 13.0, 14.3, 15.0]
iy = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0,\
500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0,\
610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0,\
714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,\
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7,\
19.9]
arr = np.column_stack((ix, iy))
target = np.concatenate((np.ones(35), np.zeros(14)))
out_data = Table.from_numpy(domain, arr, target)
3. Data Sampler 위젯에서 훈련데이터와 검증데이터로 나눔니다.

4. Test and Scode Widget에서 확인합니다.

5. Predictions Widget을 선택하여 확인합니다.




댓글 없음:
댓글 쓰기